문서 기반 AI 챗봇, 15분 만에 직접 만드는 법: RAG Agent 완전 정복
방대한 사내 문서나 매뉴얼을 AI가 직접 읽고 답변해주는 RAG Agent를 n8n으로 구축하는 방법을 단계별로 알아봅니다. 벡터 데이터베이스부터 AI 에이전트 설정까지, 비개발자도 따라할 수 있는 실전 가이드입니다.
혹시 이런 경험이 있으신가요?

새로운 직원이 입사했습니다. 첫날부터 질문이 쏟아집니다. "연차는 언제부터 생기나요?", "겸업은 가능한가요?", "출퇴근 시간이 어떻게 되나요?" HR 담당자는 매번 수십 페이지짜리 취업규칙 문서를 뒤적이며 답변해야 합니다.
고객 서비스 팀도 마찬가지입니다. 신입 상담원이 배송 지연 환불 요청을 받았을 때, 두꺼운 응대 매뉴얼을 실시간으로 검색하면서 고객과 대화를 이어가야 합니다.
만약 이 모든 문서를 AI가 대신 읽고, 직원이나 고객의 질문에 즉시 답변해준다면 어떨까요?
이것이 바로 오늘 소개할 RAG Agent(랙 에이전트)가 해결하는 문제입니다.
RAG란 무엇인가? 도서관 사서 비유로 이해하기

RAG는 Retrieval-Augmented Generation(검색 증강 생성)의 줄임말입니다. 어려운 말처럼 들리지만, 사실 매우 직관적인 개념입니다.
도서관 사서를 떠올려보세요. 누군가 "한국 전쟁에 대해 알려주세요"라고 물으면, 사서는 머릿속에 있는 기억만으로 답하지 않습니다. 먼저 관련 책을 찾아서 꺼내고, 그 내용을 참고해서 정확한 답변을 제공합니다.
RAG가 바로 이 방식입니다:
- 검색(Retrieval): 질문과 관련된 문서 내용을 찾아옵니다
- 증강(Augmented): 찾아온 내용을 질문에 추가합니다
- 생성(Generation): AI가 그 맥락을 바탕으로 답변을 만들어냅니다
왜 문서를 그냥 AI에게 던져주면 안 될까?
"그냥 문서 전체를 ChatGPT에 붙여넣으면 되지 않나요?" 라고 생각할 수 있습니다. 실제로 짧은 문서라면 가능합니다. 하지만 두 가지 문제가 생깁니다.
| 방법 | 문제점 |
|---|---|
| 문서 전체를 AI에 입력 | 컨텍스트 한계 초과, 답변 품질 저하, 비용 증가 |
| RAG 방식 | 관련 부분만 선별해서 전달, 정확도 높음, 비용 효율적 |
100페이지 문서에서 딱 1페이지 내용이 필요한데, 100페이지를 전부 AI에게 읽히는 것은 비효율적입니다. RAG는 필요한 1페이지만 정확히 찾아서 AI에게 전달합니다.
RAG의 작동 원리: 5단계로 이해하기
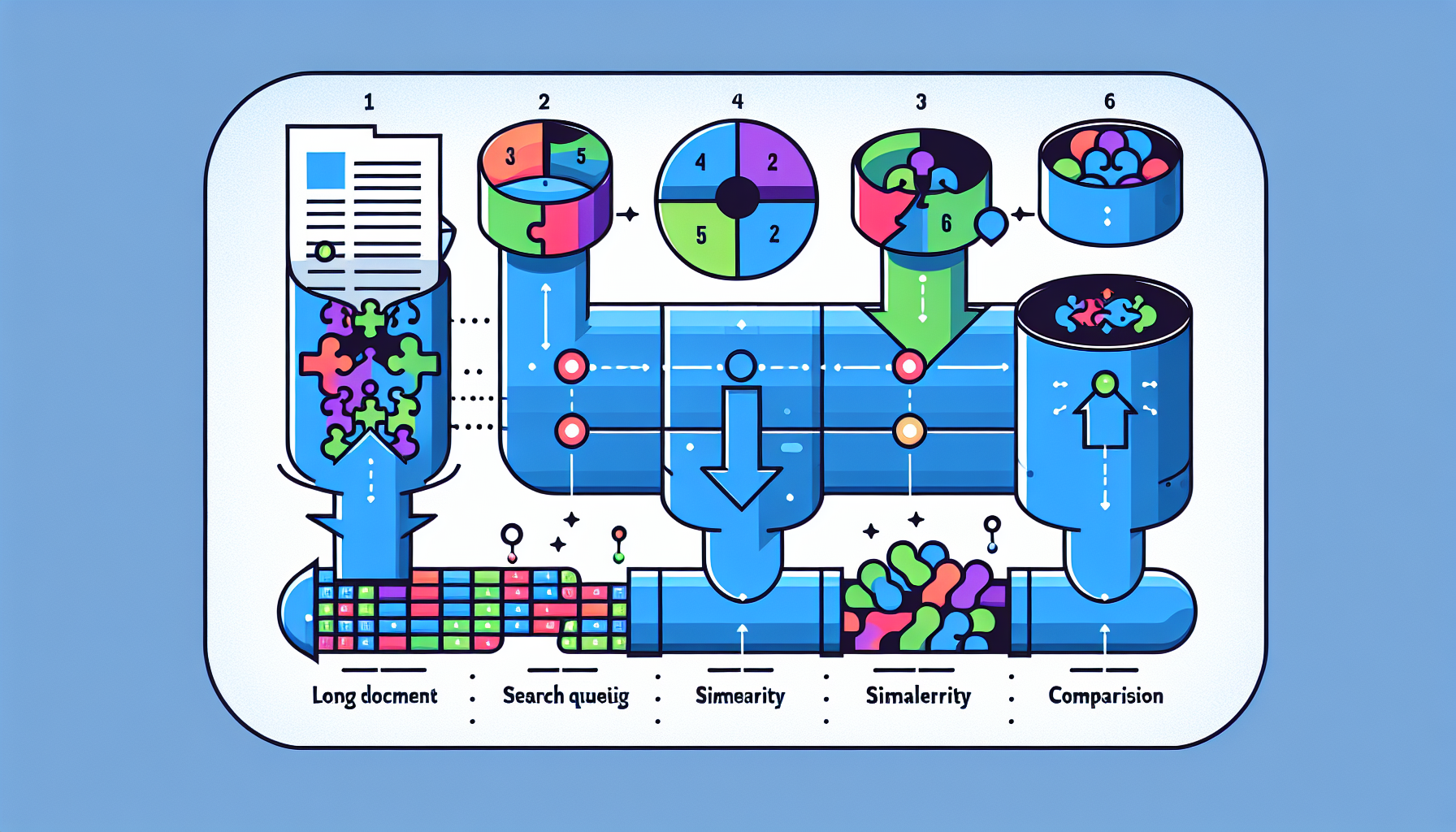
📥 문서 저장 단계 (1~3단계)
1단계: 청킹(Chunking) - 문서를 조각내기
긴 문서를 그대로 저장하지 않습니다. 문단이나 문장 단위로 잘게 쪼갭니다. 이 조각들을 '청크(Chunk)'라고 부릅니다.
💡 비유: 책 한 권을 포스트잇 수백 장에 나눠 적는 것과 같습니다. 나중에 필요한 내용의 포스트잇만 골라낼 수 있습니다.
2단계: 임베딩(Embedding) - 숫자로 변환하기
각 청크를 벡터(Vector, 숫자의 배열)로 변환합니다. 예를 들어 OpenAI의 text-embedding-3-small 모델은 텍스트를 1,536개의 숫자로 구성된 벡터로 변환합니다.
💡 왜 숫자로 변환할까요? 컴퓨터가 "겸업 금지"와 "부업 제한"이 비슷한 의미라는 것을 이해하려면, 의미가 비슷한 단어들이 수학적으로도 가까운 숫자값을 가져야 합니다. 임베딩은 이 '의미의 거리'를 숫자로 표현하는 작업입니다.
3단계: 벡터 데이터베이스에 저장
변환된 벡터값을 벡터 데이터베이스(Vector Database)에 저장합니다. 일반 데이터베이스가 텍스트를 그대로 저장한다면, 벡터 데이터베이스는 의미 기반의 숫자 값을 저장해서 유사도 검색이 가능합니다.
🔍 질문 처리 단계 (4~5단계)
4단계: 질문도 벡터로 변환 후 유사 청크 검색
사용자가 질문을 입력하면, 그 질문도 동일한 임베딩 모델로 벡터화합니다. 그런 다음 데이터베이스에 저장된 청크들과 수학적으로 비교해서 가장 유사한 청크들을 찾아냅니다.
⚠️ 중요: 문서를 저장할 때 사용한 임베딩 모델과 질문을 변환할 때 사용하는 임베딩 모델이 반드시 동일해야 합니다. 다른 모델을 사용하면 비교 자체가 의미 없어집니다.
5단계: 관련 청크 + 질문을 LLM에 전달해 답변 생성
선별된 청크들을 질문과 함께 GPT-4.1 같은 언어 모델에 전달합니다. AI는 이 맥락을 바탕으로 정확한 답변을 생성합니다.
n8n으로 RAG Agent 만들기: 실전 구축 가이드
이제 실제로 n8n(노코드 자동화 플랫폼)을 사용해서 RAG Agent를 만들어보겠습니다. 크게 두 개의 워크플로우가 필요합니다.
🛠️ 사전 준비물
- n8n 계정 (자체 호스팅 또는 클라우드)
- Supabase 계정 (무료 플랜으로 시작 가능, supabase.com)
- OpenAI API 키 (임베딩 및 LLM 사용)
- Google Drive 계정 (문서 소스로 활용)
파트 1: 문서 → 벡터 데이터베이스 저장 워크플로우
Step 1: Supabase 프로젝트 및 벡터 테이블 생성
Supabase는 PostgreSQL 기반의 오픈소스 데이터베이스 서비스로, 벡터 저장 기능까지 무료로 제공합니다.
- supabase.com에서 새 프로젝트 생성
- 프로젝트 이름과 데이터베이스 비밀번호 설정 (비밀번호는 반드시 기록해두세요)
- 리전은 Seoul 선택 권장
- 프로젝트 생성 후 SQL Editor에서 아래 작업 수행
n8n의 Supabase Vector Store 노드 문서에서 제공하는 SQL 코드를 복사해서 실행합니다. 이 코드는:
pgvector익스텐션 활성화 (벡터 연산 지원)documents테이블 생성 (1,536차원 벡터 저장)- 유사도 검색 함수(
match_documents) 생성
Step 2: n8n 워크플로우 구성
노드 1: Google Drive 트리거
- 특정 폴더에 파일이 추가될 때 자동 실행
- 폴더 감지 주기 설정 (예: 매 1분)
노드 2: Google Drive 파일 다운로드
- 트리거에서 감지된 파일 ID를 사용해 파일 다운로드
- Google Docs, PDF 등 다양한 형식 지원
노드 3: Supabase Vector Store (문서 저장)
- Operation: Add Documents
- 연결 설정: Supabase 프로젝트 URL + Service Role Secret Key
- 테이블: documents
서브 설정 - 문서 로더(Document Loader):
- 데이터 타입: Binary (다운로드된 파일)
- 텍스트 스플리터: Recursive Character Text Splitter 권장
- 일반 스플리터는 단어 중간에서 잘릴 수 있음
- Recursive 방식은 문단 → 문장 → 단어 순서로 자연스럽게 분할
- 메타데이터 추가: 파일명을
document_title로 저장
- 여러 문서를 같은 테이블에 저장할 때 출처 구분 가능
서브 설정 - 임베딩 모델:
- OpenAI
text-embedding-3-small선택 - 이 모델은 1,536차원 벡터 생성 (테이블 설정과 일치)
📌 실전 팁: 취업규칙 문서(27장 분량)를 저장하면 약 21개 청크로 분할되어 저장됩니다. 각 청크는 약 1,000자 내외이며, 200자 오버랩으로 문맥이 이어집니다.
파트 2: AI Agent 워크플로우
Step 1: 트리거 설정
When chat message received 노드를 사용합니다. 이 노드는 채팅 인터페이스를 통해 메시지를 받을 때 워크플로우를 실행합니다.
Step 2: AI Agent 노드 구성
시스템 프롬프트 예시:
당신은 회사 문서를 기반으로 답변하는 AI 어시스턴트입니다.
반드시 제공된 문서 내용만을 참고하여 답변하세요.
문서에서 관련 정보를 찾을 수 없는 경우, "해당 문서에는 관련 정보가 없습니다"라고 답변하세요.
모든 답변은 한국어로 작성하세요.
LLM 모델: GPT-4.1 (정확한 문서 이해 및 답변 생성)
Step 3: Supabase Vector Store 툴 연결
- Operation Mode: Retrieve Documents (AI Agent의 검색 도구로 활용)
- 툴 설명(Description): "회사 내부 문서에서 관련 정보를 검색하는 도구입니다"
- 테이블: documents
- 메타데이터 포함: 활성화
- 검색 결과 수(Limit): 4 (기본값, 필요에 따라 조정)
- 임베딩 모델: 문서 저장 시와 동일한
text-embedding-3-small반드시 선택
Step 4: 메모리 설정 (선택사항)
대화 맥락을 기억하게 하려면 메모리 설정이 필요합니다.
| 메모리 유형 | 특징 | 적합한 상황 |
|---|---|---|
| Simple Memory | 현재 세션만 기억, 설정 간단 | 간단한 테스트, 개인 사용 |
| PostgreSQL Chat Memory | DB에 영구 저장, 이력 조회 가능 | 팀 공유, 대화 분석 필요 시 |
Supabase는 PostgreSQL을 내장하고 있어, PostgreSQL Chat Memory를 별도 서버 없이 바로 사용할 수 있습니다. Supabase 프로젝트의 Connection String(Transaction Pooler)을 사용해 연결합니다.
실제 활용 시나리오

시나리오 1: 사내 HR 자동 응답 봇
상황: 직원이 "입사 6개월이 안 됐는데 연차를 쓸 수 있나요?"라고 질문
RAG Agent 처리 과정:
- 질문을 벡터화
- 취업규칙 문서의 청크들과 유사도 비교
- "연차", "월차", "입사 초기 휴가" 관련 청크 4개 선별
- 선별된 청크 + 질문을 GPT-4.1에 전달
- 답변: "입사 1개월 개근 시 1일의 월차가 발생하며, 발생한 당월 내 사용이 원칙입니다. 따라서 6개월 미만 재직자도 매달 1일씩 발생하는 월차를 사용할 수 있습니다."
시나리오 2: 고객 서비스 응대 가이드 봇
상황: 신입 CS 상담원이 "배송 지연으로 환불을 요청하는 고객을 어떻게 응대하나요?"라고 질문
RAG Agent는 CS 매뉴얼 PDF에서 환불 처리 절차를 찾아 단계별로 안내합니다:
- 고객의 환불 의사 확인
- 환불 금액 계산 및 안내
- 처리 절차 설명
시나리오 3: 복수 문서 통합 검색
동일한 documents 테이블에 취업규칙, CS 매뉴얼, 제품 카탈로그 등 여러 문서를 저장할 수 있습니다. 메타데이터의 document_title로 출처를 구분하기 때문에, AI Agent는 질문에 따라 적절한 문서에서 답변을 찾아냅니다.
주의사항 및 한계
⚠️ RAG Agent를 사용할 때 알아야 할 것들
1. 문서 품질이 답변 품질을 결정합니다
입력 문서가 명확하고 잘 구조화되어 있을수록 AI 답변의 정확도가 높아집니다. 스캔된 이미지 PDF나 표 위주의 문서는 텍스트 추출이 어려울 수 있습니다.
2. 청크 크기 조정이 필요할 수 있습니다
기본값(1,000자)이 항상 최적은 아닙니다. 법률 문서처럼 조항 단위로 의미가 완결되는 문서는 청크 크기를 조정하는 것이 좋습니다.
3. 문서 업데이트 시 재저장 필요
원본 문서가 변경되면 벡터 데이터베이스도 업데이트해야 합니다. 이전 버전의 청크가 남아 있으면 오래된 정보로 답변할 수 있습니다.
4. 할루시네이션 방지를 위한 시스템 프롬프트
"문서에 없는 내용은 답변하지 말라"는 지시를 시스템 프롬프트에 명확히 넣어야 합니다. 그렇지 않으면 AI가 문서에 없는 내용을 지어낼 수 있습니다.
팀 전체가 사용하는 방법

RAG Agent를 혼자만 쓰는 것이 아니라 팀 전체가 활용하려면:
- n8n 채팅 인터페이스의 Public URL 공유
- Slack 봇 연동: n8n과 Slack을 연결해서 슬랙 채널에서 직접 질문
- 웹사이트 임베드: 고객 대면 서비스라면 웹사이트에 챗봇으로 삽입
핵심 정리
- 🔍 RAG = 검색 + 생성: AI가 문서에서 관련 내용을 찾아서 답변을 만드는 구조로, 방대한 사내 문서를 AI가 대신 읽어주는 역할을 합니다
- 📦 벡터 데이터베이스: 문서를 숫자(벡터)로 변환해 저장하는 특수 DB로, Supabase를 무료로 활용할 수 있습니다
- ⚙️ 임베딩 모델 일관성: 문서 저장 시와 질문 처리 시 반드시 동일한 임베딩 모델을 사용해야 정확한 검색이 가능합니다
- 📝 메타데이터 활용: 여러 문서를 하나의 테이블에 저장할 때 파일명 등 메타데이터를 함께 저장하면 출처 추적이 용이합니다
- 🚀 n8n으로 노코드 구현: 복잡한 RAG 파이프라인을 코딩 없이 n8n 워크플로우로 15분 내에 구축할 수 있습니다